This is a post in a series about the Apache CouchDB 3.0 release. Check out the other posts in this series.
Apache CouchDB 3.0 comes equipped with a new partitioned database feature, offering more performant, scalable, and efficient querying of secondary indexes.
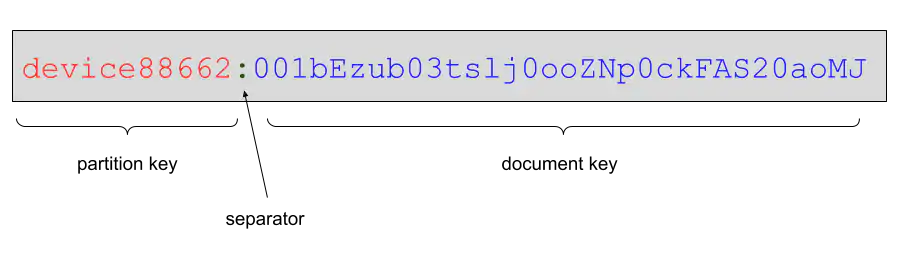
Users decide, at database creation time, whether or not to create the database with partitions. All documents in a partitioned database require a partition key, and all documents within a partition are grouped together. Common partition keys could include usernames, IoT device IDs, or locations. Partitioned database documents also have an _id field, but the _id field is in two parts, the partition key and the document key, separated by a “:” character:
Querying against a secondary index for a partition scans only the specified partition range within a single shard. Compared against a “global” query that requires collating the results of reading a copy of every shard, partition queries require much fewer resources and respond faster at scale. To visualize the difference in database operations, compare a global query on left with a partition query on right:

Querying a partitioned database with a partition key can be done against the Primary Index (_all_docs), as well as a MapReduce view, Search (now available in Apache CouchDB 3.0), or Mango index. Users can combine both partitioned and global indexes within the same database to meet their querying requirements.
For more information on leveraging Partitioned Databases in Apache CouchDB, check out the following resources:
- Apache CouchDB Reference Guide: Partitioned Databases (requires switch to stable URL) for an overview of the feature, how to create partitioned databases, and an example data model.
- Apache CouchDB API Reference: Partitioned Databases (requires switch to stable URL) for API details on querying against a partition.
- A four-part series on the IBM Cloudant blog around Partitioned Databases applicable to Apache CouchDB users:

The Road to CouchDB 3.0 – CouchDB Blog